Use Virtual Entities to show CDS snapshot data from Data lake
- 4 minutes read - 772 wordsOutline
- Export CDS data to Data lake
- Register Azure Query Accelerator
- Set up Azure Function
- Set up Virtual Entity (plugin, datasource and dataprovider)
- Conclusion
I have had two implementations this past year where clients wanted to store historical opportunity data in order to measure how the pipeline grows or shrinkens over time. The common approach has been to create a new entity, lets call it opportunity history, and run monthly batch jobs that take all opportunities and create them as an read only record in opportunity history entity. Storing a lot of data inside CDS just for the sake of reporting allways felt wrong to me. Also CDS storage is expensive. Here I suggest an alternative approach where we instead export the opportunity data to a datalake and use the brand new Azure Query Accelerator to query the csv-files with SQL-like syntax. Furthermore this functionality is exposed as an api that can be used by Virtual Entities in Dynamics365. Also the virtual entity can be used by PowerBI for reporting. This solution will give you a cleaner Dataverse with less unneccesary records in the system while still being able to see the records in the system.
Export CDS data to Datalake
Create an Azure data lake store gen 2 and go to https://make.powerapps.com/ => Data => Export to data lake. Nishantrana has a really good guide about this here
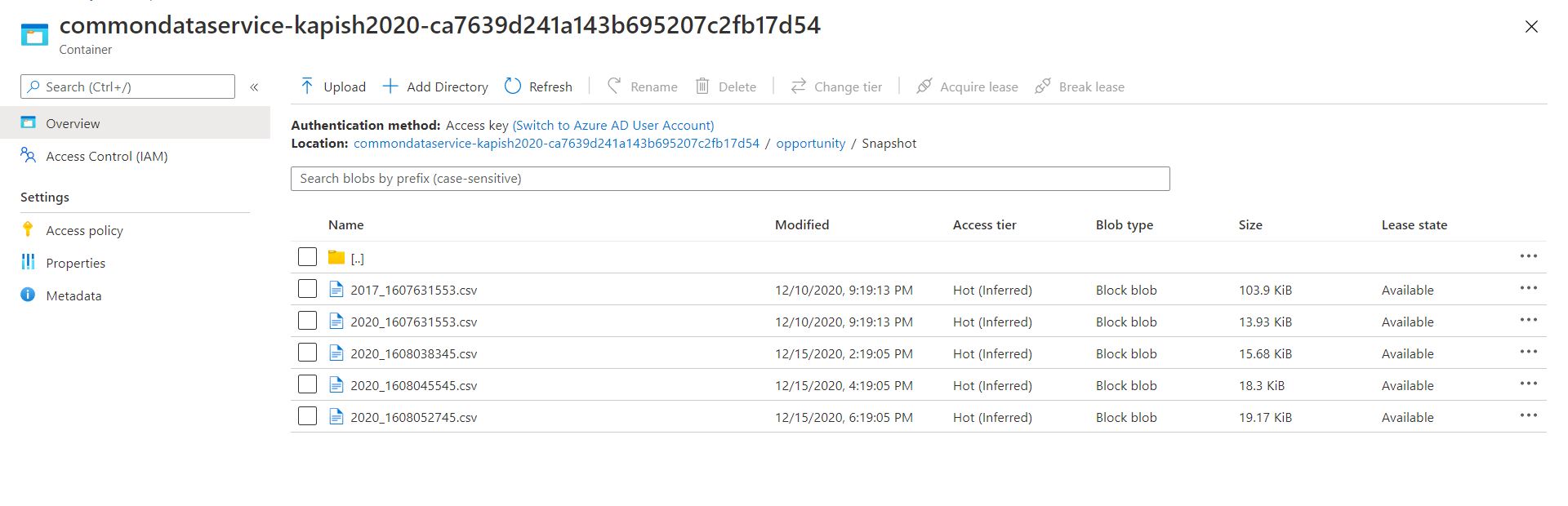
When everything is set up you will see csv-files with data from Dataverse being saved to the storage account.
Register Azure Query Accelerator
Set up the Azure Query Accelerator on your subscription using the following guide.
Set up Azure Function
Set up an azure function that will work as the api to be used by the Virtual Entities. Inside the azure function add dependency to Azure Storage Blobs (12.6) and CSVHelper. Get the connection string of your Azure data lake store gen 2 and connect to the storage. Get the container where your files are stored and find the model.json-file. I use this file in order to find the header columns of the csv-files.
var connection = Environment.GetEnvironmentVariable("azureconnection");
var containerName = "commondataservice-kapish2020-ca7639d241a143b695207c2fb17d54";
BlobContainerClient container = new BlobContainerClient(connection, containerName);
var model = container.GetBlobs().Where(blb => blb.Name == "model.json").FirstOrDefault();
var blobC = new BlobClient(connection, containerName, model.Name);
var resp = await blobC.DownloadAsync();
StringBuilder sb = new StringBuilder();
using (var streamReader = new StreamReader(resp.Value.Content))
{
while (!streamReader.EndOfStream)
{
var line = await streamReader.ReadLineAsync();
sb.Append(line);
}
}
dynamic modeldata = JsonConvert.DeserializeObject(sb.ToString());
JObject jobject = modeldata;
JObject entity = (JObject)jobject.GetValue("entities").FirstOrDefault();
var attributes = entity.GetValue("attributes");
List<string> attributesList = new List<string>();
foreach (var att in attributes)
{
attributesList.Add(((JObject)att).GetValue("name").ToString());
}When the attributes are retrieved, find the snapshot file (or you can loop through several files if you want) and apply a SQL-query to only get the data you actually need from the file.
var blobs = container.GetBlobs().Where(blb => blb.Name == "opportunity/Snapshot/2020_1608038345.csv");
List<OpportunityHistory> opportunities = new List<OpportunityHistory>();
foreach (var blob in blobs)
{
log.LogInformation(blob.Name);
var blockBlob = new BlockBlobClient(connection, containerName, blob.Name);
opportunities.AddRange(await QueryFile(blockBlob, log, attributesList));
}
return new OkObjectResult(opportunities); static async Task<List<OpportunityHistory>> QueryFile(BlockBlobClient blob, ILogger log, List<string> attributes)
{
var id = attributes.FindIndex(str => str == "Id") + 1;
var snapshotdate = attributes.FindIndex(str => str == "SinkModifiedOn") + 1;
var estimatedvalue = attributes.FindIndex(str => str == "estimatedvalue") + 1;
var name = attributes.FindIndex(str => str == "name")+1;
string query = $"SELECT _{id}, _{snapshotdate}, _{estimatedvalue}, _{name} FROM BlobStorage";
return await DumpQueryCsv(blob, query, false, log, attributes);
}The result from the query is then saved in a List and returned to be used by the Virtual entities. The entire code can be found on github.
Set up Virtual Entity (plugin, datasource and dataprovider)
Lastly create the Virtual Entity and the fields and views that you need. Set up the DataProvider, DataSource and set up the RetrieveMultiple (and Retrieve if you want) plugin in Dynamics365. Lattimer has a very good guide about how to do this.
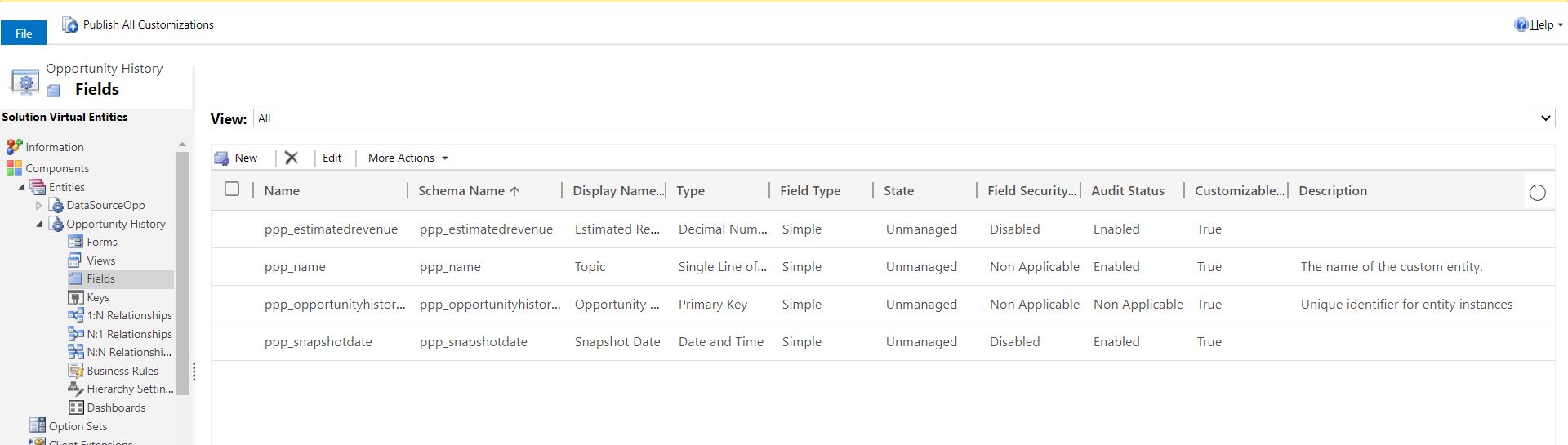
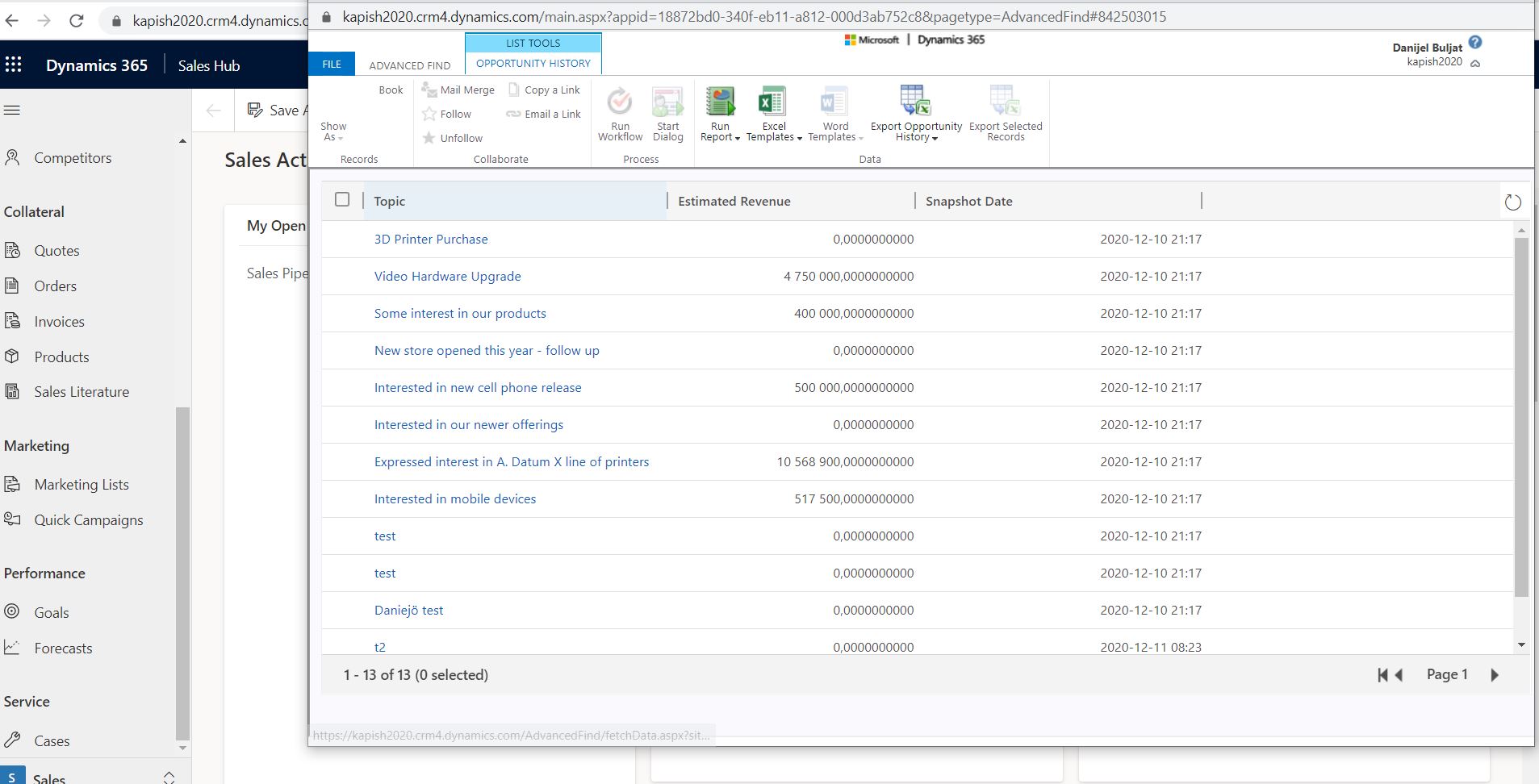
Conclusion
Now you can see your snapshot data inside dynamics as well as use it inside PowerBI to make reports and measure how the pipeline changes over time.
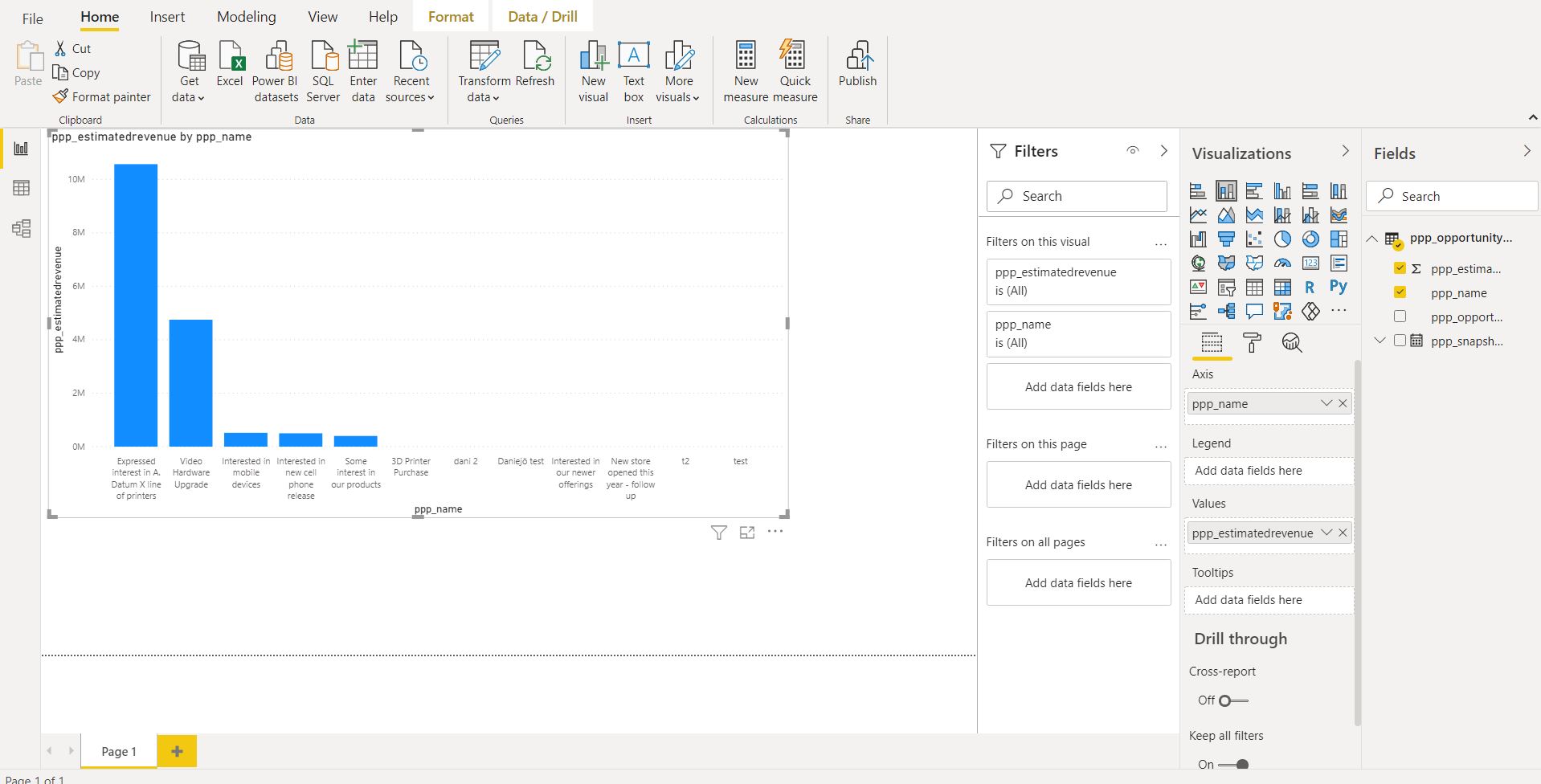
If you don’t need or want to use virtual entities you could also just read in the data directly from the storage account in to PowerBi and create pipeline reports based on this.
Storing data in data lake storage gen2 costs 0,046 USD per GB if you use a Hot storage with RA GRS. The cost of querying the data is also very low, see more info here. Storing the same data in the CDS is much more expensive. In my opinion this is a smooth and cost effective way of using datawarehouse-like features inside CDS while still keeping the system clean.